What is the goal of the project ?
The Short Answer: Assisting Airbnb hosts to set appropriate price for their listings
The Problem: Currently there is no convenient way for a new Airbnb host to decide the price of his or her listing. New hosts must often rely on the price of neighbouring listings when deciding on the price of their own listing.
The Solution: A Predictive Price Modelling tool whereby a new host can enter all the relevant details such as location of the listing, listing properties, available amenities etc and the Machine Learning Model will suggest the Price for the listing. The Model would have previously been trained on similar data from already existing Airbnb listings.
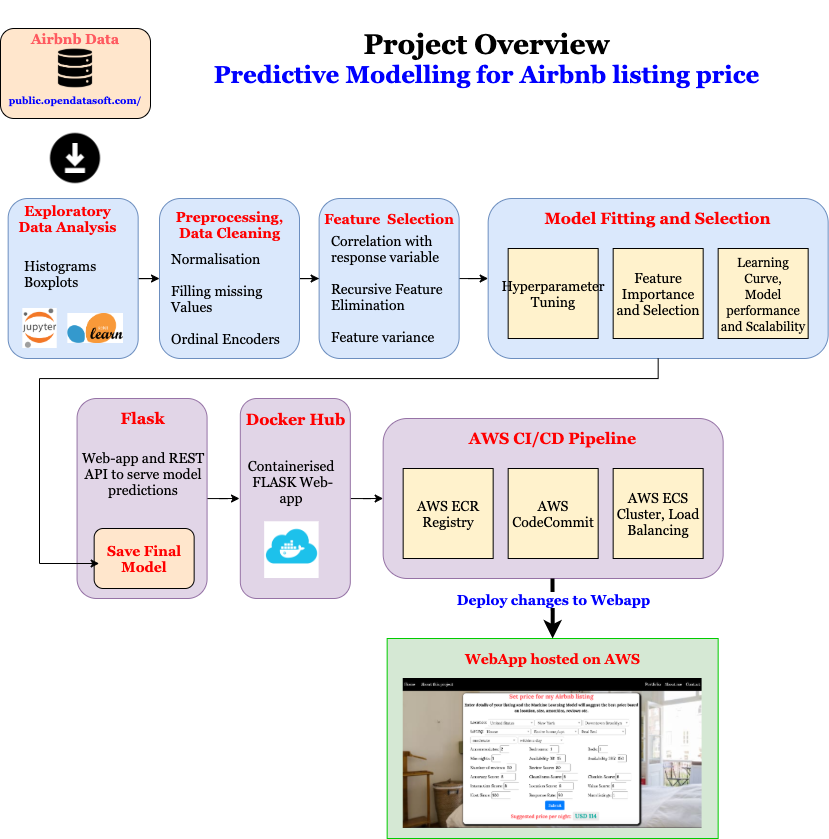
Project Overview
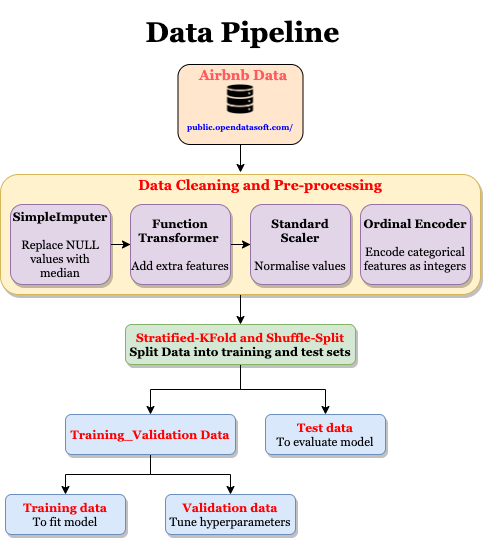
The project involved the following steps,
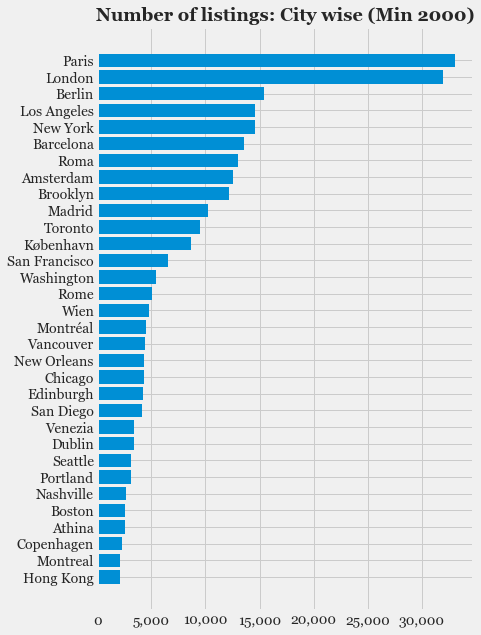
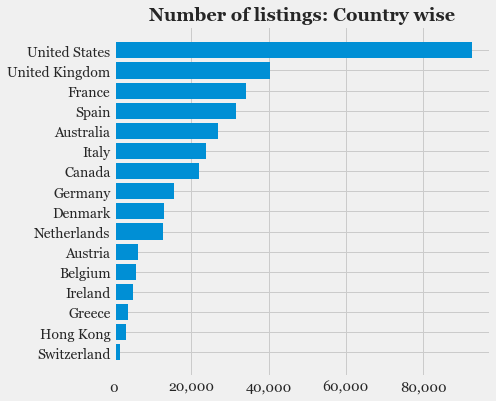
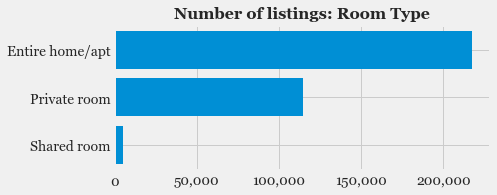
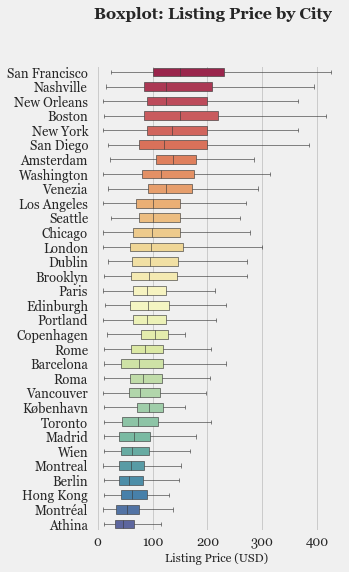
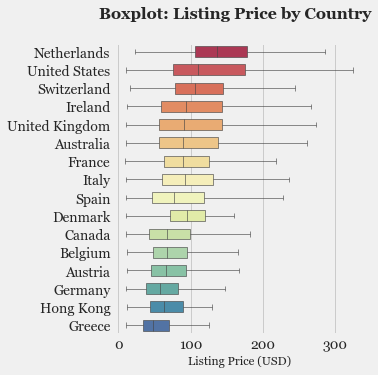
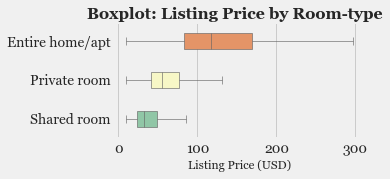
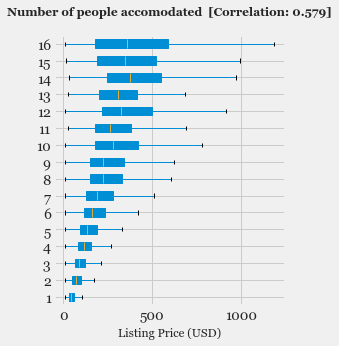
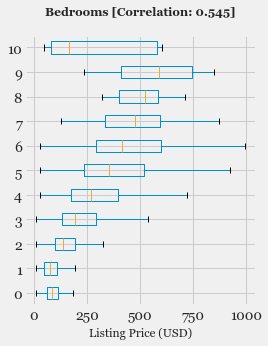
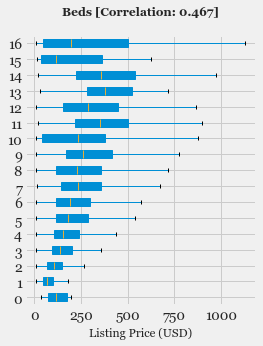
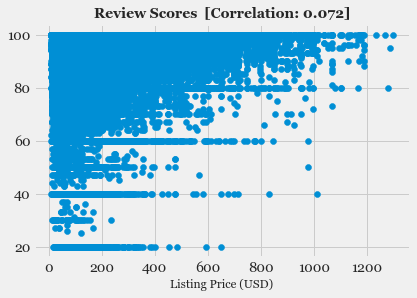
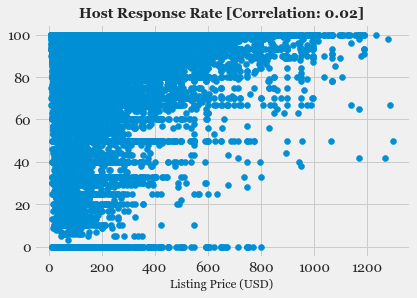
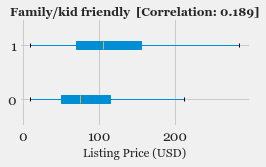
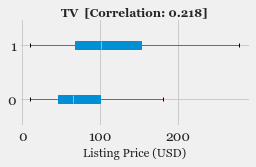
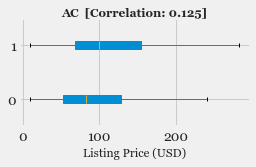
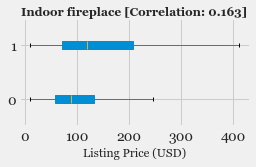
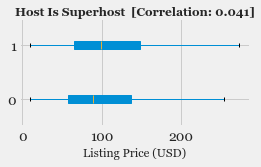
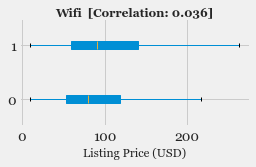
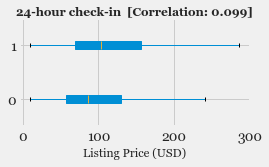
- Exploratory Data Analysis: Explore the various features, their distributions using Histograms and Box-plots
- Pre-processing and Data Cleaning: Normalisation, filling missing values, encoding categorical values
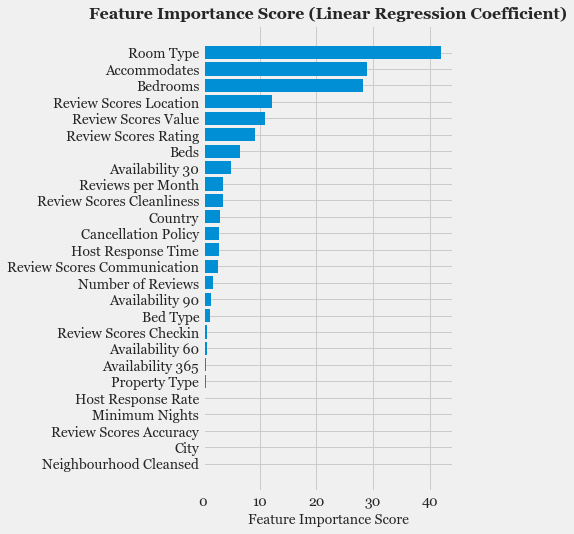
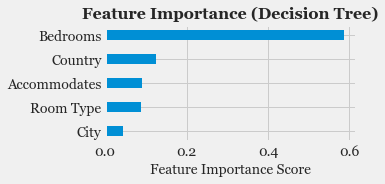
- Feature Selection: Study the correlation with response variable (Listing Price) and determine which features are most useful in predicting the price.
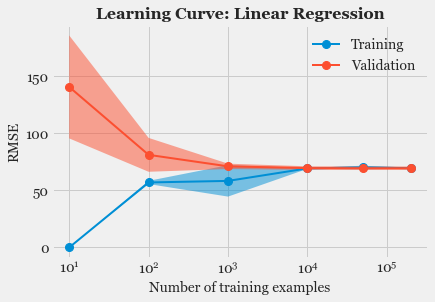
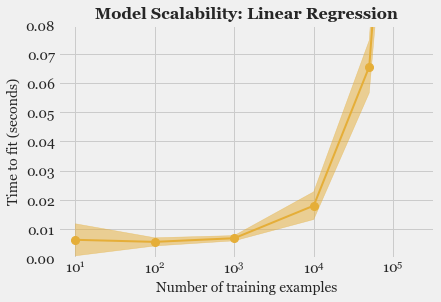
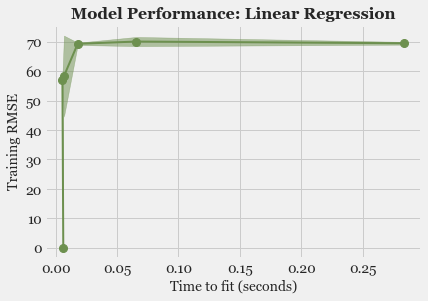
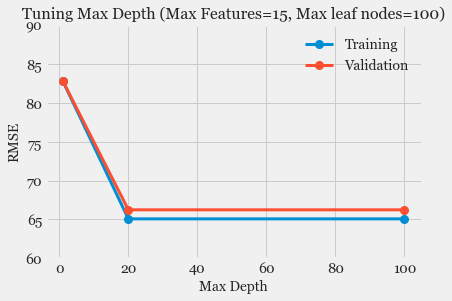
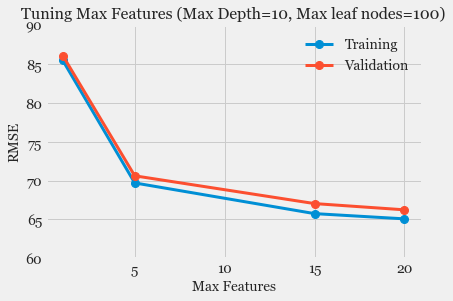
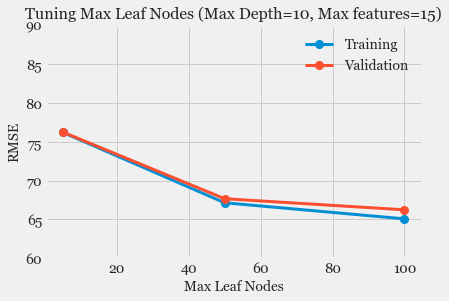
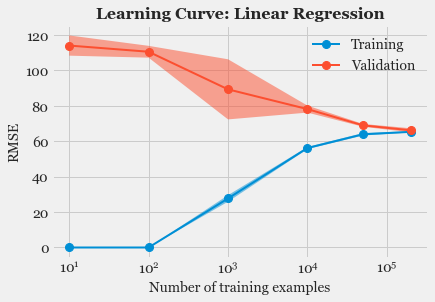
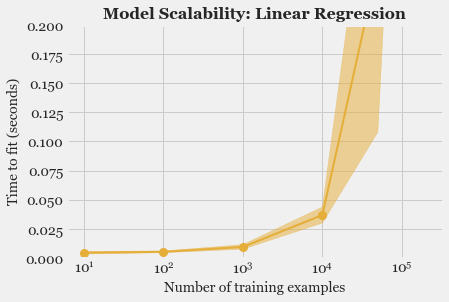
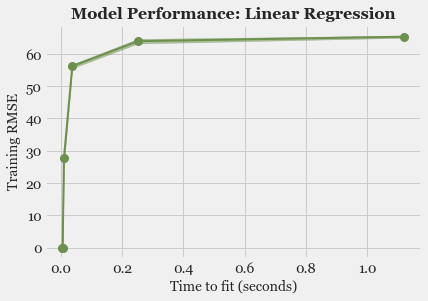
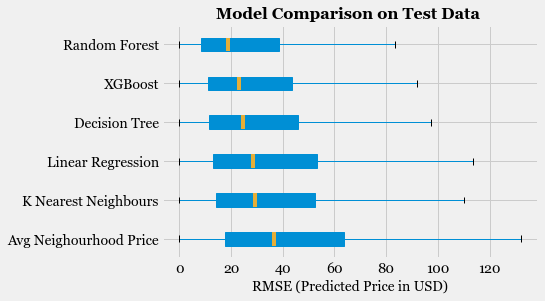
- Model Fitting and Selection: Training different models, tuning hyper-parameters and studying Model performance using Learning Curve.
- Model Serving: Using FLASK to deploy and serve Model predictions using REST API
- Container: Using Docker to containerise the Web Application
- Production: Using AWS CI/CD Pipeline for continuous integration and deployment.
End Result
The screen capture of the entire application in use is shown below. Users can enter all the relevant details of their listings, the trained Predictive Model will then predict and return the price of the listing given all the features. The Webapp can be explored here.